A traditional kernel manages machine resources and extends the machine capabilities through a system call interface, what would you say if I show you how to implement the last one? This post is about how to build a syscall interface on top of Linux.
Motivation
It seems the fastest way to test a OS design on a well provisioned environment. This article was inspired by [1]. I had wished to implement the trampoline technique too, but I want to keep this the most simple as possible.
Linux ptrace
Ptrace is a mechanism to manipulate a child process execution. It's able to:
- Stop/resume a process
- Change their saved register states
- Peek and poke data on process memory and
- Inhibit a syscall execution
Syscall emulation
Linux's x86 port (and not x86_64) supports a ptrace request called PTRACE_SYSEMU. From man page [2]:
PTRACE_SYSEMU, ...
For PTRACE_SYSEMU, continue and stop on entry to the next
system call, which will not be executed. See the
documentation on syscall-stops below. ...
These requests are currently supported only on x86.
This is what you need to implement a Trivial, Stupid and Partial OS. It is able to inhibit the normal syscall execution and to replace it by your own routine.
VKern specification
Our TSP OS will know to serve only two calls:
- 0x0: exit(): Finish the program
- 0x1: print(char *msg): Print a string pointed by msg
How it works
VKern is launched as a Linux process, it forks itself as a child process. The child process requests to be traced and loads the application process image thanks to execve. Execve is a special case, is the last call atended by the real OS before VKern control taking.
The application is the unprivileged program running under VKern control. It could call the only two VKern syscalls.
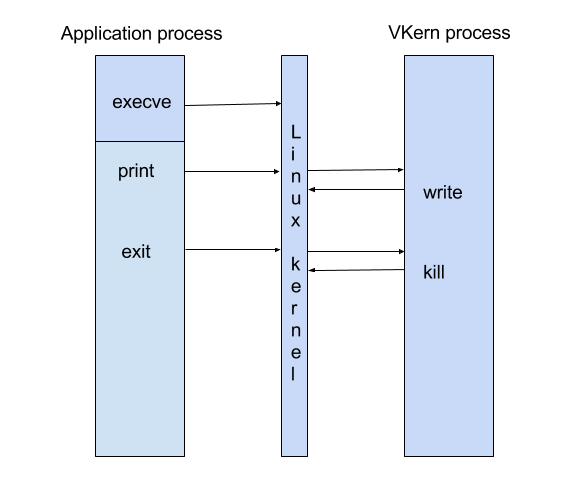
Runtime support
Call the OS from user space requires a little help beyond typical C constructions. GCC [3] gives the means to include inline assembler code like this:
__asm__ ("<assembler lines>");
Software interrupt trap
Before syscall instruction creation on x86_64 [4], a software interruption used to be executed to transfer control to the supervisor. Linux setups entry 0x80 on IDT for that purpose. So, a syscall will look as follows:
__asm__ volatile("movl %0, %%ebx\n"
"movl $1, %%eax" : "=m" (message));
__asm__ ("int $0x80");
%eax register specify the syscall number (0x0|0x1) and the remaining GP registers are the arguments.
Let's play
felipe@liedtke:~/sources/Vkern$ make
gcc -m32 vkern.c -o vkern
gcc -m32 -c rt.c -o rt.o
gcc -m32 -c hello.c -o hello.o
ld -melf_i386 hello.o rt.o -o hello
The first linked program is vkern and the second one is an example program to say Hola. Please note that hello is not linked against libc, it just uses the vkern runtime rt.o.
Finally,
felipe@liedtke:~/sources/Vkern$ ./vkern ./hello
+ Syscall number: 11:
Ignored
+ Syscall number: 1:
21198: print syscall: Hola VKern!
+ Syscall number: 1:
21198: print syscall: This syscall is managed by vkern
+ Syscall number: 0:
21198: exiting process..
+ Vkern instance finished
Code
https://github.com/astroza/vkern